Jest to kontynuacja dwóch poprzednich artykułów [2,3]. Do tej pory ładowaliśmy zindeksowane dane do pamięci Apache Solr i pytaliśmy o dane. Teraz dowiesz się jak podłączyć system zarządzania relacyjnymi bazami danych PostgreSQL [4] do Apache Solr i przeprowadzić w nim wyszukiwanie za pomocą możliwości Solr. W związku z tym konieczne jest wykonanie kilku kroków opisanych bardziej szczegółowo poniżej - konfiguracja PostgreSQL, przygotowanie struktury danych w bazie danych PostgreSQL, połączenie PostgreSQL z Apache Solr i wykonanie naszego wyszukiwania.
Krok 1: Konfiguracja PostgreSQL
O PostgreSQL - krótkie informacje
PostgreSQL to pomysłowy system zarządzania obiektowo-relacyjnymi bazami danych. Jest dostępny do użytku i był aktywnie rozwijany od ponad 30 lat. Pochodzi z Uniwersytetu Kalifornijskiego, gdzie jest postrzegany jako następca Ingresa [7].
Od samego początku jest dostępny na licencji open source (GPL), za darmo, można go modyfikować i rozpowszechniać. Jest szeroko stosowany i bardzo popularny w branży. PostgreSQL został początkowo zaprojektowany do działania tylko na systemach UNIX/Linux, a później został zaprojektowany do działania na innych systemach, takich jak Microsoft Windows, Solaris i BSD. Obecny rozwój PostgreSQL jest prowadzony przez wielu wolontariuszy na całym świecie.
Konfiguracja PostgreSQL
Jeśli jeszcze tego nie zrobiłeś, zainstaluj serwer i klienta PostgreSQL lokalnie, na przykład na Debianie GNU/Linux, jak opisano poniżej, używając apt. Dwa artykuły dotyczą PostgreSQL - artykuł Yunisa Saida [5] omawia konfigurację na Ubuntu. Mimo to tylko drapie powierzchnię, podczas gdy mój poprzedni artykuł skupia się na połączeniu PostgreSQL z rozszerzeniem GIS PostGIS [6]. Poniższy opis podsumowuje wszystkie kroki, których potrzebujemy do tej konkretnej konfiguracji.
# apt install postgresql-13 postgresql-client-13Następnie sprawdź, czy PostgreSQL działa za pomocą polecenia pg_isready. Jest to narzędzie, które jest częścią pakietu PostgreSQL.
# pg_jest gotowy/var/run/postgresql:5432 - Połączenia są akceptowane
Powyższe dane pokazują, że PostgreSQL jest gotowy i czeka na połączenia przychodzące na porcie 5432. O ile nie ustalono inaczej, jest to standardowa konfiguracja. Następnym krokiem jest ustawienie hasła dla użytkownika UNIX Postgres:
# passwd PostgresNależy pamiętać, że PostgreSQL ma własną bazę danych użytkowników, podczas gdy administrator PostgreSQL nie ma jeszcze hasła. Poprzedni krok należy również wykonać dla użytkownika PostgreSQL Postgres:
# su - Postgres$ psql -c "ALTER USER Postgres WITH PASSWORD 'hasło';"
Dla uproszczenia wybrane hasło jest tylko hasłem i powinno zostać zastąpione bezpieczniejszą frazą hasła w systemach innych niż testowe. Powyższe polecenie zmieni wewnętrzną tabelę użytkowników PostgreSQL. Zwróć uwagę na różne cudzysłowy — hasło w apostrofach, a zapytanie SQL w cudzysłowach, aby interpreter powłoki nie ocenił polecenia w niewłaściwy sposób. Dodaj także średnik po zapytaniu SQL przed podwójnymi cudzysłowami na końcu polecenia.
Następnie ze względów administracyjnych połącz się z PostgreSQL jako użytkownik Postgres z wcześniej utworzonym hasłem. Polecenie nazywa się psql:
$ psqlPołączenie z Apache Solr do bazy PostgreSQL odbywa się jako użytkownik solr. Dodajmy więc użytkownika PostgreSQL solr i ustawmy dla niego odpowiednie hasło solr za jednym razem:
$ UTWÓRZ UŻYTKOWNIKA solr Z HASŁEM 'solr';Dla uproszczenia wybrane hasło jest po prostu solr i powinno zostać zastąpione bezpieczniejszą frazą hasła na systemach, które są w produkcji.
Krok 2: Przygotowanie struktury danych
Do przechowywania i pobierania danych potrzebna jest odpowiednia baza danych. Poniższe polecenie tworzy bazę samochodów należących do użytkownika solr i będzie używana później.
$ UTWÓRZ BAZĘ DANYCH samochodów Z WŁAŚCICIELEM = solr;Następnie połącz się z nowo utworzonymi samochodami z bazą danych jako użytkownik solr. Opcja -d (krótka opcja dla -dbname) definiuje nazwę bazy danych, a -U (krótka opcja dla -username) nazwę użytkownika PostgreSQL.
$ psql -d samochody -U solrPusta baza danych nie jest przydatna, ale uporządkowane tabele z zawartością już nie. Utwórz strukturę wagonów stołowych w następujący sposób:
$ UTWÓRZ TABELĘ samochodów (ID int,
zrobić varchar(100),
model varchar(100),
opis varchar(100),
kolor warchar(50),
cena int
);
Tabliczki zawierają sześć pól danych - id (integer), make (ciąg o długości 100), model (ciąg o długości 100), opis (ciąg o długości 100), kolor (ciąg o długości 50) i cena (liczba całkowita). Aby uzyskać przykładowe dane, dodaj następujące wartości do samochodów tabeli jako instrukcje SQL:
$ WSTAWIĆ SAMOCHODY (ID, marka, model, opis, kolor, cena)WARTOŚCI (1, „BMW”, „X5”, „Fajny samochód”, „szary”, 45000);
$ WSTAWIĆ SAMOCHODY (ID, marka, model, opis, kolor, cena)
WARTOŚCI (2, „Audi”, „Quattro”, „samochód wyścigowy”, „biały”, 30000);
Rezultatem są dwie wpisy reprezentujące szare BMW X5 za 45000 USD, określane jako fajny samochód, oraz białe wyścigowe Audi Quattro za 30000 USD.
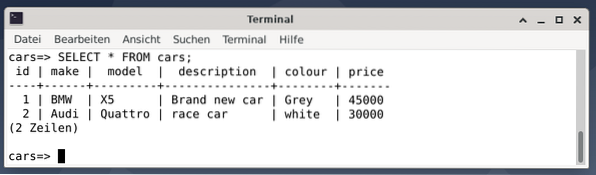
Następnie wyjdź z konsoli PostgreSQL za pomocą \q lub wyjdź.
$ \qKrok 3: Łączenie PostgreSQL z Apache Solr
Połączenie PostgreSQL i Apache Solr opiera się na dwóch programach - sterowniku Java dla PostgreSQL o nazwie Java Database Connectivity (JDBC) oraz rozszerzeniu konfiguracji serwera Solr. Sterownik JDBC dodaje interfejs Java do PostgreSQL, a dodatkowy wpis w konfiguracji Solr mówi Solr jak połączyć się z PostgreSQL za pomocą sterownika JDBC.
Dodanie sterownika JDBC odbywa się jako użytkownik root w następujący sposób i instaluje sterownik JDBC z repozytorium pakietów Debiana:
# apt-get install libpostgresql-jdbc-javaPo stronie Apache Solr również musi istnieć odpowiedni węzeł. Jeśli jeszcze tego nie zrobiłeś, jako solr użytkownika UNIX, utwórz samochody węzła w następujący sposób:
$ bin/solr utwórz -c samochodyNastępnie rozszerz konfigurację Solr dla nowo utworzonego węzła. Dodaj poniższe linie do pliku /var/solr/data/cars/conf/solrconfig.XML:
db-data-config.xmlPonadto utwórz plik /var/solr/data/cars/conf/data-config.xml i zapisz w nim następującą zawartość:
Powyższe wiersze odpowiadają poprzednim ustawieniom i definiują sterownik JDBC, określ port 5432 do połączenia z DBMS PostgreSQL jako solr użytkownika z odpowiednim hasłem i ustaw zapytanie SQL, które ma być wykonywane z PostgreSQL. Dla uproszczenia jest to instrukcja SELECT, która obejmuje całą zawartość tabeli.
Następnie uruchom ponownie serwer Solr, aby aktywować zmiany. Jako użytkownik root wykonaj następujące polecenie:
# systemctl restart solrOstatnim krokiem jest import danych np. za pomocą interfejsu webowego Solr. Pole wyboru węzła wybiera samochody węzła, a następnie z menu Węzeł poniżej wpisu Import danych, a następnie wybór pełnego importu z menu Polecenia bezpośrednio do niego. Na koniec naciśnij przycisk Wykonaj. Poniższy rysunek pokazuje, że Solr pomyślnie zindeksował dane.
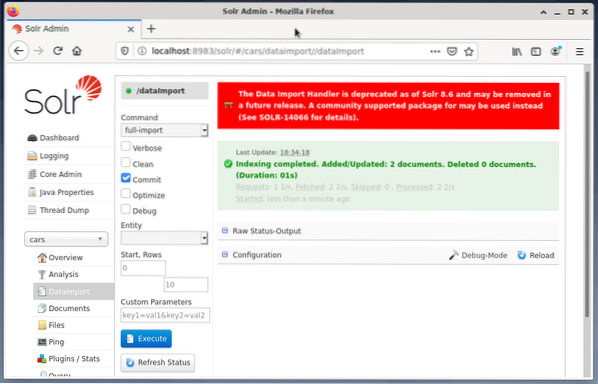
Krok 4: Zapytanie o dane z DBMS
Poprzedni artykuł [3] zajmuje się szczegółowym zapytaniem o dane, pobraniem wyniku i wyborem pożądanego formatu wyjściowego - CSV, XML lub JSON. Odpytywanie danych odbywa się podobnie do tego, czego się nauczyłeś wcześniej i żadna różnica nie jest widoczna dla użytkownika. Solr wykonuje całą pracę za kulisami i komunikuje się z systemem DBMS PostgreSQL podłączonym zgodnie z definicją w wybranym rdzeniu lub klastrze Solr.
Korzystanie z Solr nie ulega zmianie, a zapytania można przesyłać za pomocą interfejsu administratora Solr lub za pomocą curl lub wget w wierszu poleceń. Wysyłasz żądanie Get z określonym adresem URL do serwera Solr (zapytanie, aktualizacja lub usunięcie). Solr przetwarza żądanie używając DBMS jako jednostkę pamięci i zwraca wynik żądania. Następnie przetwórz odpowiedź lokalnie.
Poniższy przykład pokazuje wynik zapytania „/select?q=*. *” w formacie JSON w interfejsie administratora Solr. Dane są pobierane z bazy danych samochodów, które stworzyliśmy wcześniej.
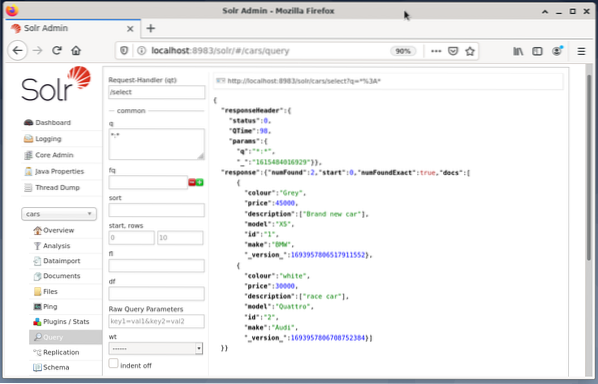
Wniosek
Ten artykuł pokazuje, jak odpytywać bazę danych PostgreSQL z Apache Solr i wyjaśnia odpowiednią konfigurację. W kolejnej części tej serii dowiesz się, jak połączyć kilka węzłów Solr w klaster Solr.
O Autorach
Jacqui Kabeta jest ekologiem, zapalonym badaczem, trenerem i mentorem. W kilku krajach afrykańskich pracowała w branży IT i środowiskach NGO.
Frank Hofmann jest programistą IT, trenerem i autorem i woli pracować w Berlinie, Genewie i Kapsztadzie. Współautor książki o zarządzaniu pakietami Debiana dostępnej w dpmb.organizacja
Linki i referencje
- [1] Apache Solr, https://lucene.Apache.org/solr/
- [2] Frank Hofmann i Jacqui Kabeta: Wprowadzenie do Apache Solr. Część 1, https://linuxhint.com/apache-solr-konfiguracja-węzła/
- [3] Frank Hofmann i Jacqui Kabeta: Wprowadzenie do Apache Solr. Odpytywanie danych. Część 2, http://linuxhint.com
- [4] PostgreSQL, https://www.postgresql.organizacja/
- [5] Younis Said: Jak zainstalować i skonfigurować bazę danych PostgreSQL na Ubuntu 20.04, https://linuxhint.com/install_postgresql_-ubuntu/
- [6] Frank Hofmann: Konfiguracja PostgreSQL z PostGIS na Debianie GNU/Linux 10, https://linuxhint.com/setup_postgis_debian_postgres/
- [7] Ingres, Wikipedia, https://en.Wikipedia.org/wiki/Ingres_(baza danych)


