Na przykład, jeśli chcesz otrzymywać regularne aktualizacje swoich ulubionych produktów z ofertami rabatowymi lub chcesz zautomatyzować proces pobierania odcinków ulubionego sezonu jeden po drugim, a strona internetowa nie ma do tego żadnego API, to jedyny wybór Pozostaje ci web scraping.Web scraping może być nielegalny na niektórych stronach internetowych, w zależności od tego, czy strona na to pozwala, czy nie. Strony internetowe używają „robotów.txt” w celu jawnego zdefiniowania adresów URL, których nie można usuwać. Możesz sprawdzić, czy strona na to pozwala, czy nie, dodając „roboty.txt” z nazwą domeny witryny. Na przykład https://www.Google.com/roboty.tekst
W tym artykule użyjemy Pythona do scrapingu, ponieważ jest bardzo łatwy w konfiguracji i użyciu. Ma wiele wbudowanych i zewnętrznych bibliotek, które mogą być używane do scrapingu i organizowania danych. Użyjemy dwóch bibliotek Pythona „urllib” do pobrania strony internetowej i „BeautifulSoup” do przeanalizowania strony internetowej w celu zastosowania operacji programistycznych.
Jak działa skrobanie stron internetowych?
Wysyłamy zapytanie na stronę, z której chcesz pobrać dane. Witryna odpowie na żądanie zawartością HTML strony. Następnie możemy przetworzyć tę stronę do BeautifulSoup w celu dalszego przetwarzania. Aby pobrać stronę internetową, użyjemy biblioteki „urllib” w Pythonie.
Urllib pobierze zawartość strony internetowej w formacie HTML. Nie możemy zastosować operacji na ciągach znaków na tej stronie HTML w celu wyodrębnienia treści i dalszego przetwarzania. Wykorzystamy bibliotekę Pythona „BeautifulSoup”, która przeanalizuje zawartość i wyodrębni interesujące dane.
Skrobanie artykułów z Linuxhint.com
Teraz, gdy mamy już pomysł na działanie web scrapingu, poćwiczmy. Postaramy się zeskrobać tytuły artykułów i linki z Linuxhint.com. Więc otwórz https://linuxhint.com/ w Twojej przeglądarce.
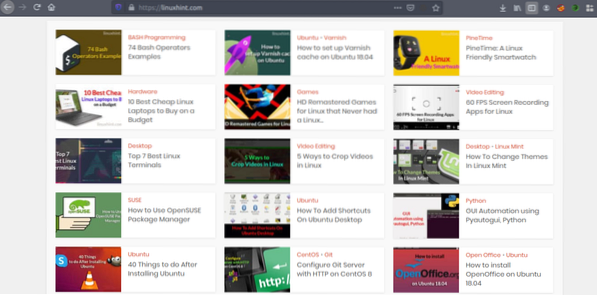
Teraz naciśnij CRTL+U, aby wyświetlić kod źródłowy HTML strony internetowej.
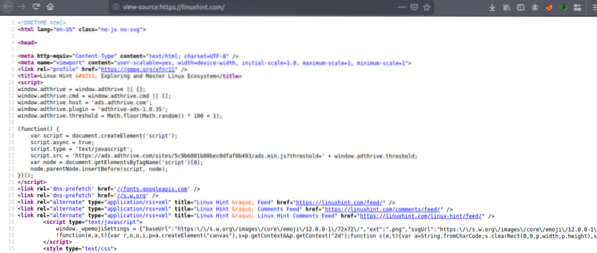
Skopiuj kod źródłowy i przejdź do https://htmlformatter.com/ upiększyć kod. Po upiększeniu kodu łatwo go sprawdzić i znaleźć ciekawe informacje.
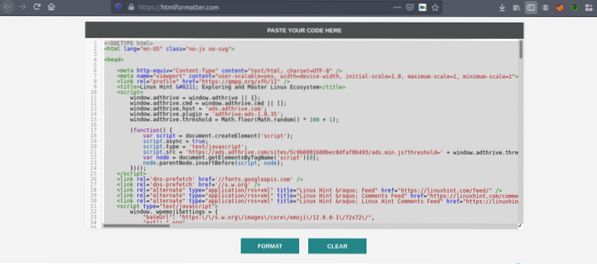
Teraz ponownie skopiuj sformatowany kod i wklej go do swojego ulubionego edytora tekstu, takiego jak atom, wysublimowany tekst itp. Teraz przeszukamy interesujące informacje za pomocą Pythona. Wpisz następujące
// Zainstaluj piękną bibliotekę zup, nadchodzi urllibpreinstalowany w Pythonie
ubuntu@ubuntu:~$ sudo pip3 zainstaluj bs4
ubuntu@ubuntu:~$ python3
Pyton 3.7.3 (domyślnie, 7 października 2019, 12:56:13)
[RWP 8.3.0] na Linuksie
Wpisz „pomoc”, „prawa autorskie”, „kredyty” lub „licencja”, aby uzyskać więcej informacji.
//Importuj bibliotekę url>>> importuj bibliotekę url.żądanie
//Importuj piękną zupę
>>> import z bs4 BeautifulSoup
//Wprowadź adres URL, który chcesz pobrać
>>> mój_url = 'https://linuxhint.pl/'
//Zażądaj adresu URL za pomocą polecenia urlopen
>>> klient = urllib.żądanie.urlopen(mój_url)
//Przechowuj stronę internetową HTML w zmiennej „html_page”
>>> html_page = klient.czytać()
//Zamknij połączenie URL po pobraniu strony internetowej
>>> klient.blisko()
//przeanalizuj stronę HTML do BeautifulSoup do skrobania
>>> page_soup = PięknaZupa(html_page, "html.parser")
Teraz spójrzmy na kod źródłowy HTML, który właśnie skopiowaliśmy i wkleiliśmy, aby znaleźć interesujące nas rzeczy.
Widać, że pierwszy artykuł na Linuxhint.com nosi nazwę „74 przykłady operatorów Bash”, znajdź to w kodzie źródłowym. Jest zawarty między tagami nagłówka, a jego kod to
title="74 Przykłady operatorów Bash">74 Operatory Bash
Przykłady
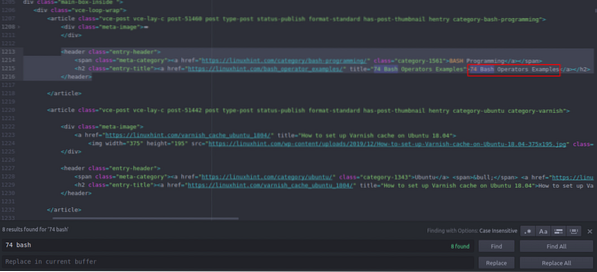
Ten sam kod powtarza się w kółko ze zmianą samych tytułów artykułów i linków. Następny artykuł zawiera następujący kod HTML
title="Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04">
Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04
Widać, że wszystkie artykuły, w tym te dwa, są ujęte w tym samym „
” i użyj tej samej klasy „tytuł-wpisu”. Możemy użyć funkcji „znajdź wszystko” w bibliotece Piękna zupa, aby znaleźć i wyświetlić wszystkie „” mający klasę „tytuł-wpisu”. Wpisz następujące polecenie w konsoli Pythona // To polecenie znajdzie wszystkie „” elementy znaczników o nazwie klasy
„tytuł-wpisu”. Dane wyjściowe zostaną zapisane w tablicy.
>>> artykuły = zupa_strona.znajdźWszystko("h2" ,
"klasa" : "tytuł-wpisu")
// Liczba artykułów znalezionych na stronie głównej Linuxhint.com
>>> len(artykuły)
102
// Pierwszy wyodrębniony „” element tagu zawierający nazwę artykułu i link
>>> artykuły[0]
title="74 Przykłady operatorów Bash">
74 Przykłady operatorów Bash
// Drugi wyodrębniony „” element tagu zawierający nazwę artykułu i link
>>> artykuły[1]
title="Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04">
Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04
// Wyświetlanie tylko tekstu w znacznikach HTML za pomocą funkcji tekstowej
>>> artykuły[1].tekst
'Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18?.04'
” elementy znaczników o nazwie klasy
„tytuł-wpisu”. Dane wyjściowe zostaną zapisane w tablicy.
>>> artykuły = zupa_strona.znajdźWszystko("h2" ,
"klasa" : "tytuł-wpisu")
// Liczba artykułów znalezionych na stronie głównej Linuxhint.com
>>> len(artykuły)
102
// Pierwszy wyodrębniony „” element tagu zawierający nazwę artykułu i link
>>> artykuły[0]
title="74 Przykłady operatorów Bash">
74 Przykłady operatorów Bash
// Drugi wyodrębniony „” element tagu zawierający nazwę artykułu i link
>>> artykuły[1]
title="Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04">
Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04
// Wyświetlanie tylko tekstu w znacznikach HTML za pomocą funkcji tekstowej
>>> artykuły[1].tekst
'Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18?.04'
>>> artykuły[0]
title="74 Przykłady operatorów Bash">
74 Przykłady operatorów Bash
// Drugi wyodrębniony „
” element tagu zawierający nazwę artykułu i link
>>> artykuły[1]
title="Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04">
Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04
// Wyświetlanie tylko tekstu w znacznikach HTML za pomocą funkcji tekstowej
>>> artykuły[1].tekst
'Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18?.04'
title="Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04">
Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04
Teraz, gdy mamy listę wszystkich 102 HTML „
” elementy tagów zawierające link do artykułu i tytuł artykułu. Możemy wyodrębnić zarówno linki do artykułów, jak i tytuły. Aby wyodrębnić linki z „” tagi, możemy użyć następującego kodu // Poniższy kod wyodrębni link z pierwszego element tagu
>>> dla linku w artykułach[0].find_all('a', href=True):
… print(link['href'])
…
https://linuxhint.com/bash_operator_examples/
Teraz możemy napisać pętlę for, która iteruje przez każdy „
” oznaczyć element na liście „artykuły” i wyodrębnić link do artykułu oraz tytuł. >>> dla i w zakresie (0,10):
… drukuj(artykuły[i].tekst)
… dla linku w artykułach[i].find_all('a', href=True):
… print(link['href']+"\n")
…
74 Przykłady operatorów Bash
https://linuxhint.com/bash_operator_examples/
Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04
https://linuxhint.com/varnish_cache_ubuntu_1804/
PineTime: smartwatch przyjazny dla Linuksa
https://linuxhint.pl/pinetime_linux_smartwatch/
10 najlepszych tanich laptopów z systemem Linux do kupienia z ograniczonym budżetem
https://linuxhint.com/best_cheap_linux_laptops/
Zremasterowane gry HD dla Linuksa, które nigdy nie zostały wydane na Linuksa…
https://linuxhint.com/hd_remastered_games_linux/
Aplikacje do nagrywania ekranu 60 FPS dla systemu Linux
https://linuxhint.com/60_fps_screen_recording_apps_linux/
74 Przykłady operatorów Bash
https://linuxhint.com/bash_operator_examples/
… ciach…
Podobnie zapisujesz te wyniki w pliku JSON lub CSV.
Wniosek
Twoje codzienne zadania to nie tylko zarządzanie plikami czy wykonywanie poleceń systemowych. Możesz także zautomatyzować zadania związane z siecią, takie jak automatyzacja pobierania plików lub ekstrakcja danych, poprzez scraping sieci w Python. Ten artykuł ograniczał się tylko do prostej ekstrakcji danych, ale możesz wykonać ogromną automatyzację zadań za pomocą „urllib” i „BeautifulSoup”.
>>> dla linku w artykułach[0].find_all('a', href=True):
… print(link['href'])
…
https://linuxhint.com/bash_operator_examples/
… drukuj(artykuły[i].tekst)
… dla linku w artykułach[i].find_all('a', href=True):
… print(link['href']+"\n")
…
74 Przykłady operatorów Bash
https://linuxhint.com/bash_operator_examples/
Jak skonfigurować pamięć podręczną lakierów na Ubuntu 18.04
https://linuxhint.com/varnish_cache_ubuntu_1804/
PineTime: smartwatch przyjazny dla Linuksa
https://linuxhint.pl/pinetime_linux_smartwatch/
10 najlepszych tanich laptopów z systemem Linux do kupienia z ograniczonym budżetem
https://linuxhint.com/best_cheap_linux_laptops/
Zremasterowane gry HD dla Linuksa, które nigdy nie zostały wydane na Linuksa…
https://linuxhint.com/hd_remastered_games_linux/
Aplikacje do nagrywania ekranu 60 FPS dla systemu Linux
https://linuxhint.com/60_fps_screen_recording_apps_linux/
74 Przykłady operatorów Bash
https://linuxhint.com/bash_operator_examples/
… ciach…

