W tym artykule omówimy zastosowania funkcji scalania, funkcji concat i różnych typów operacji złączeń w pythonie Pandas. Wszystkie przykłady zostaną wykonane za pomocą edytora pycharm. Zacznijmy od szczegółów!
Korzystanie z funkcji scalania
Podstawowa powszechnie używana składnia funkcji merge() jest podana poniżej:
pd.scal(df_obj1, df_obj2, how='inner', on=Brak, left_on=Brak, right_on=Brak)Wyjaśnijmy szczegóły parametrów:
Pierwsze dwa df_obj1 i df_obj2 argumentami są nazwy obiektów lub tabel DataFrame.
„w jaki sposób” parametr jest używany dla różnych typów operacji łączenia, takich jak „lewe, prawe, zewnętrzne i wewnętrzne”. Funkcja scalania domyślnie używa operacji łączenia „wewnętrznego”.
Argument "na" zawiera nazwę kolumny, na której wykonywana jest operacja łączenia. Ta kolumna musi być obecna w obu obiektach DataFrame.
W argumentach „left_on” i „right_on” „left_on” to nazwa kolumny jako klucza w lewym DataFrame. „right_on” to nazwa kolumny używanej jako klucz z prawej ramki DataFrame.
Aby rozwinąć koncepcję łączenia DataFrame, wykorzystaliśmy dwa obiekty DataFrame – produkt i klient. W produkcie DataFrame znajdują się następujące szczegóły:
produkt=pd.Ramka danych(„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
DataFrame klienta zawiera następujące dane:
klient=pd.Ramka danych(„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
'Klient_Miasto': ['Lahore','Islamabad','Faisalabad','Karaczi','Karaczi','Islamabad','Rawalpindi','Islamabad',
"Lahore"]
)
Dołącz do DataFrames na klucz
Z łatwością znajdziemy produkty sprzedawane online oraz klientów, którzy je kupili. Tak więc, w oparciu o klucz „Product_ID”, wykonaliśmy operację złączenia wewnętrznego na obu DataFrame w następujący sposób:
# importuj bibliotekę Pandyimportuj pandy jako PD
produkt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
„Miasto”: [„Lahore”, „Islamabad”, „Faisalabad”, „Karaczi”, „Karaczi”, „Islamabad”, „Rawalpindi”, „Islamabad”,
"Lahore"]
)
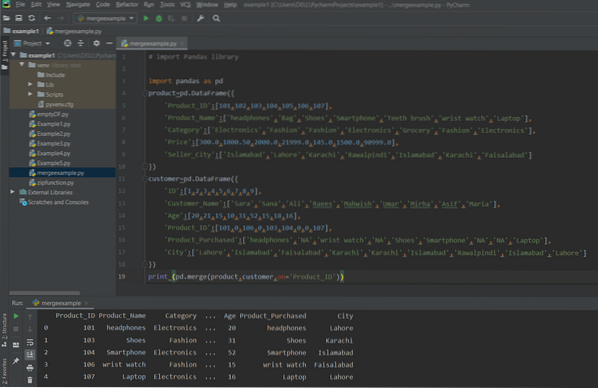
drukuj (pd.scal(produkt,klient,on='ID_produktu'))
Następujące dane wyjściowe wyświetlają się w oknie po uruchomieniu powyższego kodu:
Jeśli kolumny są różne w obu ramkach DataFrames, jawnie napisz nazwę każdej kolumny za pomocą argumentów left_on i right_on w następujący sposób:
importuj pandy jako PDprodukt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
„Miasto”: [„Lahore”, „Islamabad”, „Faisalabad”, „Karaczi”, „Karaczi”, „Islamabad”, „Rawalpindi”, „Islamabad”,
"Lahore"]
)
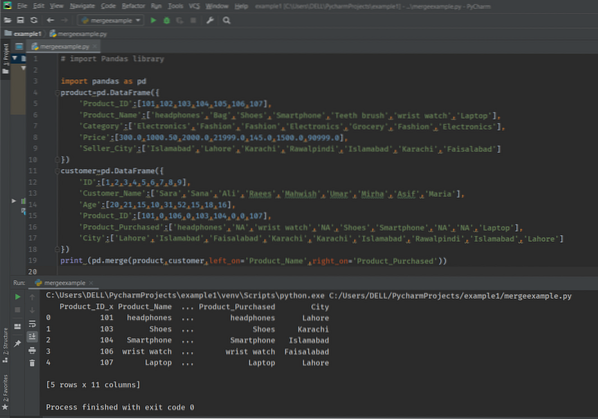
drukuj (pd.merge(product,customer,left_on='Product_Name',right_on='Product_Purchased'))
Na ekranie pojawią się następujące dane wyjściowe:
Dołącz do DataFrames za pomocą argumentu How
W poniższych przykładach wyjaśnimy cztery typy operacji Joins na Pandas DataFrames:
- Połączenie wewnętrzne
- Połączenie zewnętrzne
- Dołącz do lewej
- Prawe Dołącz
Wewnętrzne połączenie w pandach
Możemy wykonać sprzężenie wewnętrzne na wielu klawiszach. Aby wyświetlić więcej szczegółów dotyczących sprzedaży produktu, weź Product_ID, Seller_City z DataFrame produktu i Product_ID oraz „Customer_City” z elementu DataFrame klienta, aby stwierdzić, że sprzedawca lub klient należy do tego samego miasta. Zaimplementuj następujące wiersze kodu:
# importuj bibliotekę Pandyimportuj pandy jako PD
produkt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
'Klient_Miasto': ['Lahore','Islamabad','Faisalabad','Karaczi','Karaczi','Islamabad','Rawalpindi','Islamabad',
"Lahore"]
)
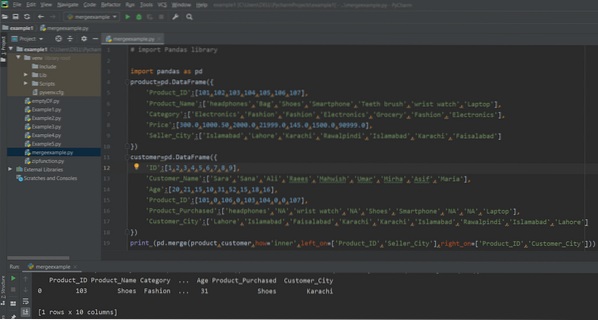
drukuj (pd.merge(product,customer,how='inner',left_on=['Product_ID','Seller_City'],right_on=['Product_ID','Customer_City']))
Poniższy wynik pokazuje się w oknie po uruchomieniu powyższego kodu:
Pełne/zewnętrzne połączenie w Pandach
Sprzężenia zewnętrzne zwracają zarówno prawe, jak i lewe wartości DataFrames, które albo mają dopasowania. Tak więc, aby zaimplementować złącze zewnętrzne, ustaw argument „jak” jako zewnętrzny. Zmodyfikujmy powyższy przykład, używając koncepcji złączenia zewnętrznego outer. W poniższym kodzie zwróci wszystkie wartości zarówno lewego, jak i prawego elementu DataFrames.
# importuj bibliotekę Pandyimportuj pandy jako PD
produkt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
'Klient_Miasto': ['Lahore','Islamabad','Faisalabad','Karaczi','Karaczi','Islamabad','Rawalpindi','Islamabad',
"Lahore"]
)
drukuj (pd.merge(product,customer,on='Product_ID',how='outer'))
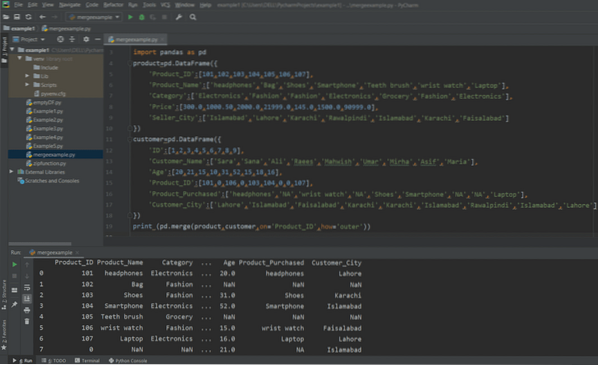
Ustaw argument wskaźnika jako „Prawda”. Zauważysz, że nowa kolumna „_merge” została dodana na końcu.
# importuj bibliotekę Pandyimportuj pandy jako PD
produkt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
'Klient_Miasto': ['Lahore','Islamabad','Faisalabad','Karaczi','Karaczi','Islamabad','Rawalpindi','Islamabad',
"Lahore"]
)
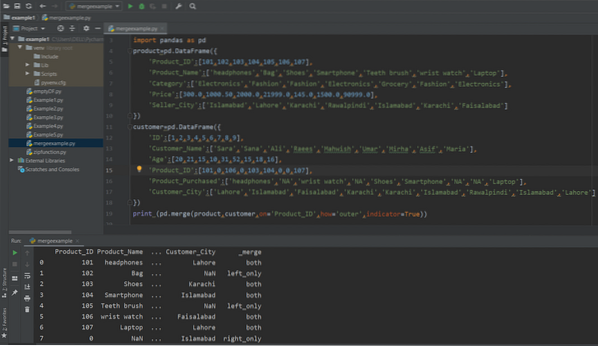
drukuj (pd.merge(product,customer,on='Product_ID',how='outer',indicator=True))
Jak widać na poniższym zrzucie ekranu, wartości kolumny scalania wyjaśniają, który wiersz należy do którego DataFrame.
Lewy Dołącz do Pand
Połączenie lewe wyświetla tylko wiersze lewego elementu DataFrame. Jest podobny do połączenia zewnętrznego. Tak więc zmień wartość argumentu „jak” na „lewo”. Wypróbuj poniższy kod, aby zaimplementować ideę Left join:
# importuj bibliotekę Pandyimportuj pandy jako PD
produkt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
'Klient_Miasto': ['Lahore','Islamabad','Faisalabad','Karaczi','Karaczi','Islamabad','Rawalpindi','Islamabad',
"Lahore"]
)
drukuj (pd.merge(product,customer,on='Product_ID',how='left'))
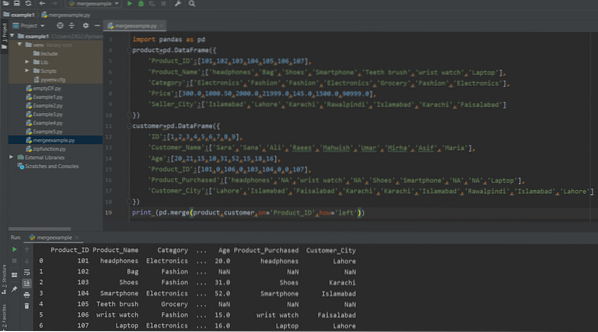
Prawe Dołącz do Pand
Prawe sprzężenie utrzymuje wszystkie prawe wiersze DataFrame po prawej stronie wraz z wierszami, które są również wspólne w lewym DataFrame. W tym przypadku argument „jak” jest ustawiony jako „właściwa” wartość. Uruchom następujący kod, aby zaimplementować koncepcję właściwego łączenia:
# importuj bibliotekę Pandyimportuj pandy jako PD
produkt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
'Klient_Miasto': ['Lahore','Islamabad','Faisalabad','Karaczi','Karaczi','Islamabad','Rawalpindi','Islamabad',
"Lahore"]
)
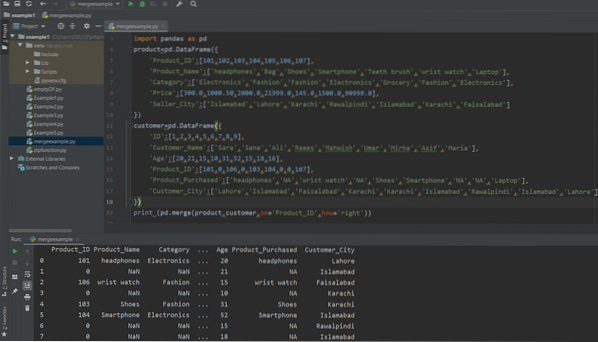
drukuj (pd.merge(product,customer,on='Product_ID',how='right'))
Na poniższym zrzucie ekranu możesz zobaczyć wynik po uruchomieniu powyższego kodu:
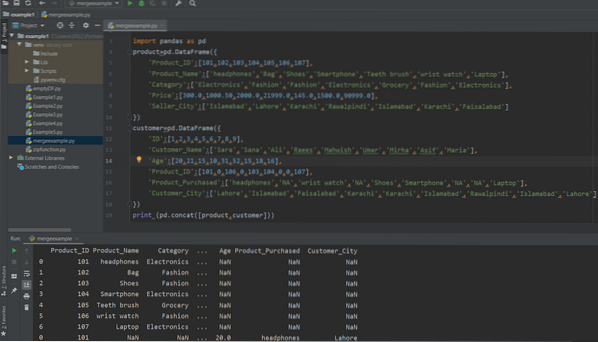
Łączenie DataFrames za pomocą funkcji Concat()
Dwie ramki DataFrame można połączyć za pomocą funkcji concat. Podstawowa składnia funkcji konkatenacji jest podana poniżej:
pd.concat([df_obj1, df_obj_2]))Dwa obiekty DataFrames przejdą jako argumenty.
Połączmy zarówno produkt DataFrames, jak i klienta poprzez funkcję concatcat. Uruchom następujące wiersze kodu, aby połączyć dwie ramki DataFrame:
# importuj bibliotekę Pandyimportuj pandy jako PD
produkt=pd.Ramka danych(
„Identyfikator produktu”:[101,102,103,104,105,106,107],
„Nazwa produktu”: [„słuchawki”, „Torba”, „Buty”, „Smartfon”, „Szczotka do zębów”, „Zegarek na rękę”, „Laptop”],
'Kategoria':['Elektronika','Moda','Moda','Elektronika','Artykuły spożywcze','Moda','Elektronika'],
„Cena”: [300.0,1000.50,2000.0,21999.0,145.0,1500.0,90999.0],
„Seller_City”: [„Islamabad”, „Lahore”, „Karaczi”, „Rawalpindi”, „Islamabad”, „Karaczi”, „Faisalabad”]
)
klient=pd.Ramka danych(
„ID”:[1,2,3,4,5,6,7,8,9],
'Nazwa_klienta': ['Sara', 'Sana', 'Ali', 'Raees', 'Mahwish', 'Umar', 'Mirha', 'Asif', 'Maria'],
'Wiek':[20,21,15,10,31,52,15,18,16],
„Identyfikator produktu”:[101,0,106,0,103,104,0,0,107],
'Produkt_Zakupiony':['słuchawki','NA','zegarek','NA','Buty','Smartfon','NA','NA','Laptop'],
'Klient_Miasto': ['Lahore','Islamabad','Faisalabad','Karaczi','Karaczi','Islamabad','Rawalpindi','Islamabad',
"Lahore"]
)
drukuj (pd.concat([produkt,klient]))
Wniosek:
W tym artykule omówiliśmy implementację funkcji merge(), concat() i operacji join w pythonie Pandas. Korzystając z powyższych metod, możesz łatwo połączyć dwa DataFrame i nauczyć się. jak zaimplementować operacje łączenia „wewnętrzne, zewnętrzne, lewe i prawe” w Pandach. Mamy nadzieję, że ten samouczek poprowadzi Cię w implementacji operacji łączenia na różnych typach DataFrames. Daj nam znać o swoich trudnościach w przypadku jakiegokolwiek błędu.


