W tym artykule pokażę, jak uzyskać aktualny adres URL przeglądarki za pomocą Selenium. Więc zacznijmy.
Wymagania wstępne:
Aby wypróbować polecenia i przykłady z tego artykułu, musisz mieć,
1) Dystrybucja Linuksa (najlepiej Ubuntu) zainstalowana na Twoim komputerze.
2) Python 3 zainstalowany na twoim komputerze.
3) PIP 3 zainstalowany na twoim komputerze.
4) Pythona wirtualne środowisko pakiet zainstalowany na twoim komputerze.
5) Przeglądarka internetowa Mozilla Firefox lub Google Chrome zainstalowana na Twoim komputerze.
6) Musisz wiedzieć, jak zainstalować sterownik Firefox Gecko lub Chrome Web Driver.
Aby spełnić wymagania 4, 5 i 6, przeczytaj mój artykuł Wprowadzenie do Selenium w Pythonie 3 w Linuxhint.com.
Możesz znaleźć wiele artykułów na inne tematy na LinuxHint.com. Sprawdź je, jeśli potrzebujesz pomocy.
Konfigurowanie katalogu projektu:
Aby wszystko było zorganizowane, utwórz nowy katalog projektów selen-url/ następująco:
$ mkdir -pv selen-url/sterowniki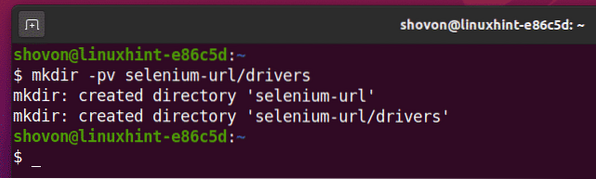
Przejdź do to selen-url/ katalog projektu w następujący sposób:
$ cd selen-url/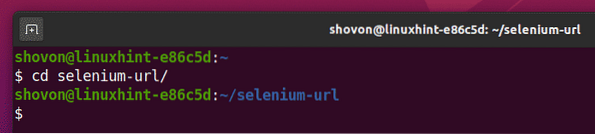
Utwórz wirtualne środowisko Pythona w katalogu projektu w następujący sposób:
$ virtualenv .venv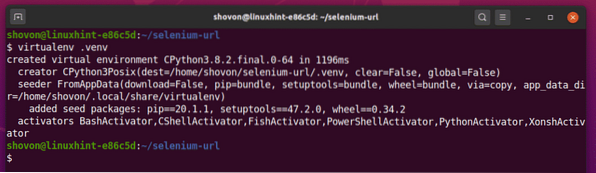
Aktywuj środowisko wirtualne w następujący sposób:
$ źródło .venv/bin/aktywuj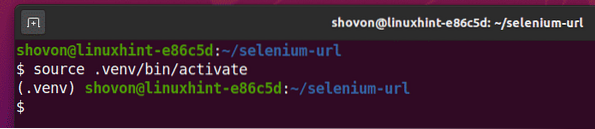
Zainstaluj bibliotekę Selenium Python w swoim środowisku wirtualnym za pomocą PIP3 w następujący sposób:
$ pip3 zainstaluj selen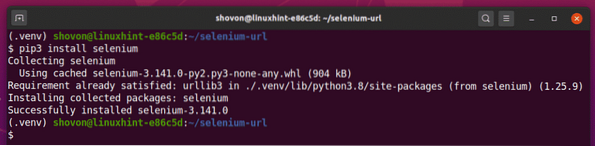
Pobierz i zainstaluj wszystkie wymagane sterowniki sieciowe w kierowcy/ katalog projektu. W moim artykule wyjaśniłem proces pobierania i instalowania sterowników internetowych Wprowadzenie do Selenium w Pythonie 3. Jeśli potrzebujesz pomocy, szukaj dalej LinuxWskazówka.com dla tego artykułu.
Do demonstracji w tym artykule będę używał przeglądarki internetowej Google Chrome. Więc będę używał chromedriver binarny z Selenium. Powinieneś użyć geckodriver binarny, jeśli chcesz używać przeglądarki internetowej Firefox.
Pobieranie bieżącego adresu URL z Selenium:
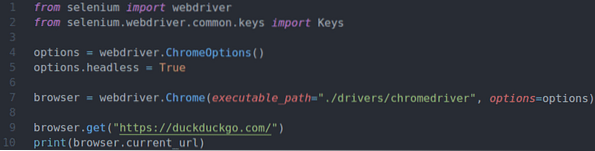
Utwórz skrypt Pythona ex01.py w katalogu swojego projektu i wpisz w nim następujące wiersze kodów.
z selen importu webdriverz selenu.webdriver.wspólny.import kluczy Klucze
opcje = sterownik sieciowy.Opcje Chrome()
opcje.bezgłowy = Prawda
przeglądarka = sterownik sieciowy.Chrome(ścieżka_wykonywania =./drivers/chromedriver", opcje=opcje)
przeglądarka.pobierz("https://kacze kacze.pl/")
drukuj (przeglądarka.bieżący_url)
przeglądarka.blisko()
Gdy skończysz, zapisz ex01.py Skrypt Pythona.
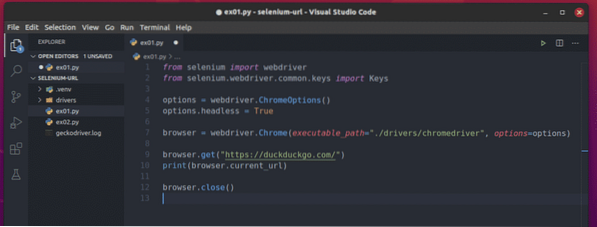
Tutaj wiersz 1 i wiersz 2 importują wszystkie wymagane komponenty z biblioteki selenowej Pythona.

Wiersz 4 tworzy obiekt Chrome Options, a wiersz 5 włącza tryb bezgłowy w przeglądarce Chrome.

Linia 7 tworzy Chrome przeglądarka obiekt używając chromedriver binarny z kierowcy/ katalog projektu.

Linia 9 mówi przeglądarce, aby załadować duckduckgo.strona internetowa com.

Linia 10 wyświetla aktualny adres URL przeglądarki. Tutaj, przeglądarka.bieżący_url właściwość służy do uzyskiwania dostępu do aktualnego adresu URL przeglądarki.

Linia 12 zamyka przeglądarkę.

Uruchom skrypt Pythona ex01.py następująco:
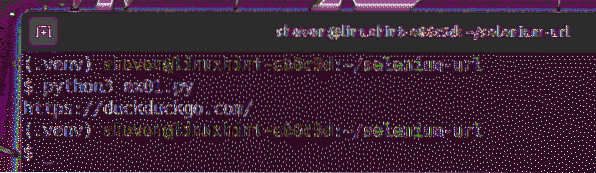
$ python3 ex01.py
Jak widać, aktualny adres URL (https://duckduckgo.com) jest wydrukowany na konsoli.
We wcześniejszym przykładzie odwiedziłem stronę duckduckgo.com i wydrukowałem aktualny adres URL na konsoli. Zwraca adres URL odwiedzanej strony. Niezbyt wyszukane, ponieważ znamy już adres URL strony page. Teraz wyszukajmy coś na DuckDuckGo i spróbujmy wydrukować adres URL strony wyników wyszukiwania na konsoli.
Utwórz skrypt Pythona ex02.py w katalogu swojego projektu i wpisz w nim następujące wiersze kodów.
z selen importu webdriverz selenu.webdriver.wspólny.import kluczy Klucze
opcje = sterownik sieciowy.Opcje Chrome()
opcje.bezgłowy = Prawda
przeglądarka = sterownik sieciowy.Chrome(ścieżka_wykonywania =./drivers/chromedriver", opcje=opcje)
przeglądarka.pobierz("https://kacze kacze.pl/")
drukuj (przeglądarka.bieżący_url)
searchInput = przeglądarka.find_element_by_id('search_form_input_homepage')
searchInput.send_keys('selenium hq' + klawisze.WCHODZIĆ)
drukuj (przeglądarka.bieżący_url)
przeglądarka.blisko()
Gdy skończysz, zapisz ex02.py Skrypt Pythona.
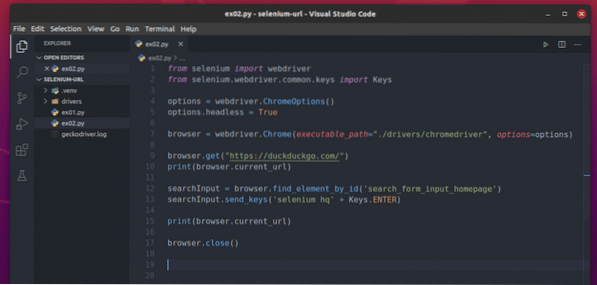
Tutaj wiersze 1-10 są takie same jak w ex01.py. Więc nie wyjaśniam ich ponownie.
Linia 12 wyszukuje pole tekstowe wyszukiwania i przechowuje je w searchInput zmienna.
Linia 13 wysyła zapytanie wyszukiwania selen hq w searchInput pole tekstowe i naciska

Po załadowaniu strony wyszukiwania, przeglądarka.bieżący_url służy do uzyskiwania dostępu do zaktualizowanego aktualnego adresu URL.
Linia 15 wyświetla zaktualizowany aktualny adres URL na konsoli.

Linia 17 zamyka przeglądarkę.

Uruchom ex02.py Skrypt Pythona w następujący sposób:
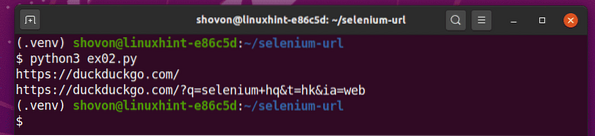
$ python3 ex02.py
Jak widać, skrypt Pythona ex02.py drukuje 2 adresy URL.
Pierwszy to adres URL strony głównej wyszukiwarki DuckDuckGo.
Drugi to zaktualizowany aktualny adres URL po przeprowadzeniu wyszukiwania w wyszukiwarce DuckDuckGo za pomocą zapytania selen hq.
Wniosek:
W tym artykule pokazałem, jak uzyskać aktualny adres URL przeglądarki internetowej za pomocą biblioteki Selenium Python. Teraz powinieneś być w stanie uatrakcyjnić swoje projekty Selenium.


