Ten artykuł pokazuje, jak znaleźć duplikaty w danych i usunąć duplikaty za pomocą funkcji Pandas Python.
W tym artykule wzięliśmy zbiór danych o populacji różnych stanów w Stanach Zjednoczonych, który jest dostępny w kilku językach .format pliku csv. Przeczytamy .plik csv, aby pokazać oryginalną zawartość tego pliku w następujący sposób:
importuj pandy jako PDstan_df=pd.read_csv("C:/Użytkownicy/DELL/Pulpit/population_ds.csv")
drukuj(stan_df)
Na poniższym zrzucie ekranu możesz zobaczyć zduplikowaną zawartość tego pliku:
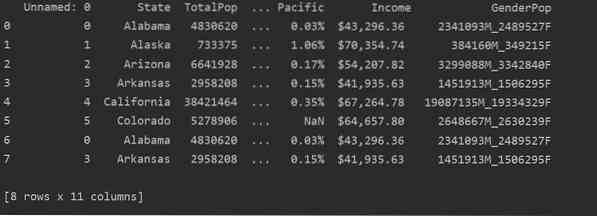
Identyfikowanie duplikatów w Pandas Python
Konieczne jest ustalenie, czy dane, których używasz, zawierają zduplikowane wiersze. Aby sprawdzić duplikację danych, możesz użyć dowolnej z metod opisanych w poniższych sekcjach.
Metoda 1:
Przeczytaj plik csv i przekaż go do ramki danych. Następnie zidentyfikuj zduplikowane wiersze za pomocą zduplikowane() funkcjonować. Na koniec użyj instrukcji print, aby wyświetlić zduplikowane wiersze.
importuj pandy jako PDdf_state=pd.read_csv("C:/Użytkownicy/DELL/Pulpit/population_ds.csv")
Dup_Rows = stan_df[stan_df.zduplikowane()]
print("\n\nPowiel wiersze: \n ".format(Dup_Row))
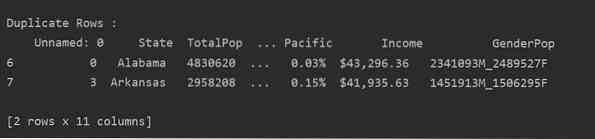
Metoda 2:
Korzystając z tej metody, jest_zduplikowany kolumna zostanie dodana na końcu tabeli i oznaczona jako 'True' w przypadku powielania wierszy.
importuj pandy jako PDdf_state=pd.read_csv("C:/Użytkownicy/DELL/Pulpit/population_ds.csv")
df_state["jest_duplikat"]= df_state.zduplikowane()
print("\n ".format(stan_df))
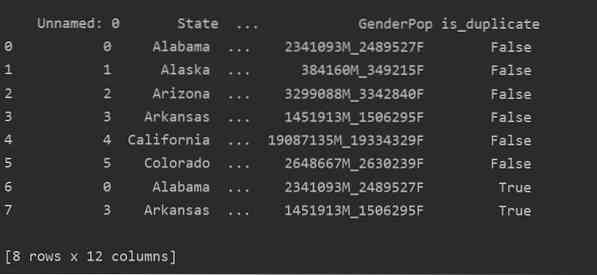
Upuszczanie duplikatów w Pythonie Pandy
Zduplikowane wiersze można usunąć z ramki danych przy użyciu następującej składni:
drop_duplicates(subset=, keep=, inplace=false)
Powyższe trzy parametry są opcjonalne i zostały szczegółowo wyjaśnione poniżej:
trzymać: ten parametr ma trzy różne wartości: First, Last i False. Wartość First zachowuje pierwsze wystąpienie i usuwa kolejne duplikaty, wartość Last zachowuje tylko ostatnie wystąpienie i usuwa wszystkie poprzednie duplikaty, a wartość False usuwa wszystkie zduplikowane wiersze.
podzbiór: etykieta używana do identyfikacji zduplikowanych wierszy
w miejscu: zawiera dwa warunki: Prawda i Fałsz. Ten parametr usunie zduplikowane wiersze, jeśli jest ustawiony na True.
Usuń duplikaty, zachowując tylko pierwsze wystąpienie
Kiedy użyjesz „keep=first”, tylko pierwsze wystąpienie wiersza zostanie zachowane, a wszystkie inne duplikaty zostaną usunięte.
Przykład
W tym przykładzie zostanie zachowany tylko pierwszy wiersz, a pozostałe duplikaty zostaną usunięte:
importuj pandy jako PDstan_df=pd.read_csv("C:/Użytkownicy/DELL/Pulpit/population_ds.csv")
Dup_Rows = stan_df[stan_df.zduplikowane()]
print("\n\nPowiel wiersze : \n ".format(Dup_Row))
DF_RM_DUP = stan_df.drop_duplicates(keep='pierwszy')
print('\n\nResult DataFrame po usunięciu duplikatu :\n', DF_RM_DUP.głowa (n=5))
Na poniższym zrzucie ekranu zachowane wystąpienie pierwszego wiersza jest podświetlone na czerwono, a pozostałe duplikaty są usuwane:
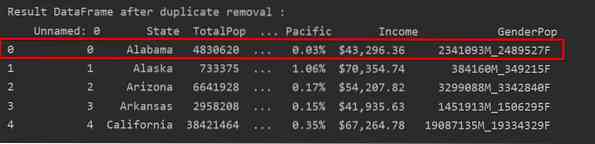
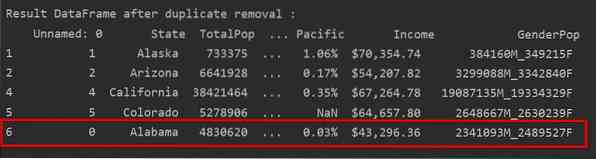
Usuń duplikaty zachowując tylko ostatnie wystąpienie O
Gdy użyjesz „keep=last”, wszystkie zduplikowane wiersze z wyjątkiem ostatniego wystąpienia zostaną usunięte.
Przykład
W poniższym przykładzie wszystkie zduplikowane wiersze są usuwane z wyjątkiem ostatniego wystąpienia.
importuj pandy jako PDdf_state=pd.read_csv("C:/Użytkownicy/DELL/Pulpit/population_ds.csv")
Dup_Rows = stan_df[stan_df.zduplikowane()]
print("\n\nPowiel wiersze : \n ".format(Dup_Row))
DF_RM_DUP = stan_df.drop_duplicates(keep='ostatni')
print('\n\nResult DataFrame po usunięciu duplikatu :\n', DF_RM_DUP.głowa (n=5))
Na poniższej ilustracji duplikaty są usuwane i zachowywane jest tylko ostatnie wystąpienie wiersza:
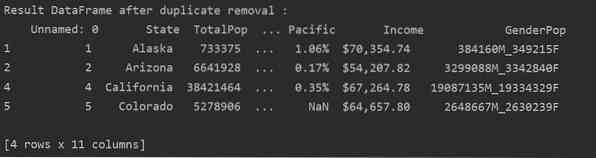
Usuń wszystkie zduplikowane wiersze
Aby usunąć wszystkie zduplikowane wiersze z tabeli, ustaw „keep=False” w następujący sposób:
importuj pandy jako PDdf_state=pd.read_csv("C:/Użytkownicy/DELL/Pulpit/population_ds.csv")
Dup_Rows = stan_df[stan_df.zduplikowane()]
print("\n\nPowiel wiersze: \n ".format(Dup_Row))
DF_RM_DUP = stan_df.drop_duplicates(zachowaj=Fałsz)
print('\n\nResult DataFrame po usunięciu duplikatu :\n', DF_RM_DUP.głowa (n=5))
Jak widać na poniższym obrazku, wszystkie duplikaty są usuwane z ramki danych:
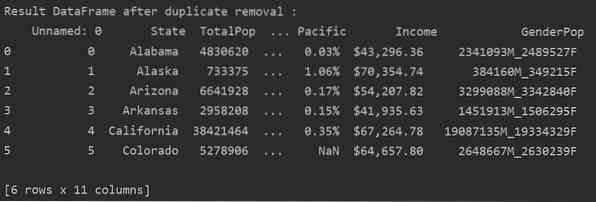
Usuń powiązane duplikaty z określonej kolumny
Domyślnie funkcja sprawdza wszystkie zduplikowane wiersze ze wszystkich kolumn w danej ramce danych. Ale możesz również określić nazwę kolumny za pomocą parametru podzbioru.
Przykład
W poniższym przykładzie wszystkie powiązane duplikaty są usuwane z kolumny „Stany”.
importuj pandy jako PDdf_state=pd.read_csv("C:/Użytkownicy/DELL/Pulpit/population_ds.csv")
Dup_Rows = stan_df[stan_df.zduplikowane()]
print("\n\nPowiel wiersze : \n ".format(Dup_Row))
DF_RM_DUP = stan_df.drop_duplicates(subset='Stan')
print('\n\nResult DataFrame po usunięciu duplikatu :\n', DF_RM_DUP.głowa (n=6))
Wniosek
W tym artykule pokazano, jak usunąć zduplikowane wiersze z ramki danych za pomocą drop_duplikaty() funkcja w Pythonie Pandy. Korzystając z tej funkcji, możesz również usunąć powielanie lub nadmiarowość danych. W artykule pokazano również, jak zidentyfikować duplikaty w ramce danych.


