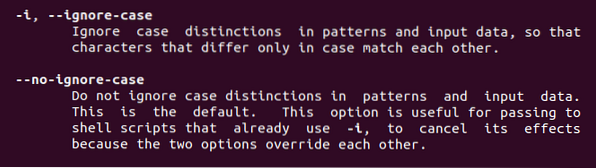
Z tego polecenia znajdziemy dwie funkcje opisane powyżej. -Mam na myśli zignorowanie przypadku, gdziekolwiek użyje się tego słowa kluczowego, afekt przypadku zostanie usunięty.
Warunek wstępny
Aby osiągnąć funkcjonalność tej funkcji w systemie operacyjnym Linux, musimy mieć zainstalowany system operacyjny Linux. Po skonfigurowaniu podasz wymagane informacje o użytkowniku, dzięki którym użytkownik zostanie zalogowany. Ponadto po podaniu nazwy użytkownika i hasła użytkownik będzie mógł uzyskać dostęp do wszystkich wbudowanych funkcji systemu operacyjnego. Wreszcie, po uzyskaniu dostępu do pulpitu musisz uzyskać dostęp do terminala, ponieważ należy na nim uruchamiać polecenia.
Przykład 1:
W tym przykładzie zobaczymy, jak grep pomaga w unikaniu rozróżniania wielkości liter. Rozważ plik o nazwie files11.tekst. Plik zawiera w sobie następujące dane; jak widać słowo mango jest napisane na różne sposoby, niektóre słowa są pisane dużymi, a niektóre małymi. Używając komendy cat wyświetlimy dane pliku.
$ cat pliki11.tekst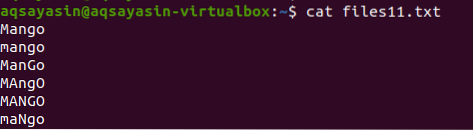
Gdy polecenie zostanie użyte do wyświetlenia danych, można zauważyć, że wyświetlane jest jedyne słowo, które odpowiada wielkości liter w poleceniu. Wszystkie litery są pisane małymi literami.
$ grep pliki mango11.tekst
Teraz, aby zrozumieć pojęcie niewrażliwości na wielkość liter, użyjemy „-I” w poleceniu, aby obsłużyć wielkość liter, dostarczając wszystkie dane obecne w pliku, pasujące do ciągu znajdującego się w poleceniu.
$ grep -I mango pliki11.tekst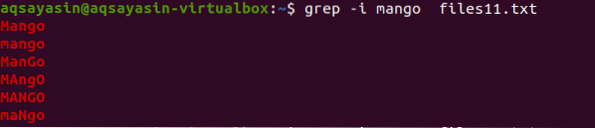
Z wyników dowiesz się, że wszystkie dane pasujące do słowa „mango” są wyświetlane z niektórymi słowami pisanymi wielkimi literami, a niektóre z małymi literami.
Przykład 2
Ten przykład jest podobny do pierwszego, różnica polega na tym, że otrzymuje się tylko jedno słowo. To polecenie pomaga w uzyskaniu całego ciągu, dopasowując go do słowa podanego w poleceniu. Pozwól nam mieć plik plika.tekst. jako przykład chcemy pobrać rekord zgodnie z podanym dopasowaniem.
$ cat filea.tekst
Teraz zastosuj to samo polecenie, aby zignorować przypadek i przedstawić wynik. Słowo techniczne jest wyświetlane po wyłączeniu wielkości liter, aby rozróżniać wielkość liter.

Przykład 3
Inną metodą użycia grep do ignorowania wielkości liter jest wprowadzenie najpierw nazwy pliku, a następnie zastosowanie polecenia -I z grep po „|” operator. Cat jest używany w połączeniu z „|”. Miejmy plik o nazwie file24.tekst. jako przykład.
$ Pilnik Cat24.tekst | grep -I „Aksa”To polecenie pobierze słowo „Aqsa” zarówno w dużych, jak i małych literach.

Przykład 4
Idąc w kierunku innego przykładu. Tutaj wyświetlimy dane pliku zawierającego słowo „my”. Tutaj wyszukiwanie odbywa się poprzez wprowadzenie katalogu, dzięki czemu polecenie posortuje słowo we wszystkich plikach mających rozszerzenie .txt w systemie.
$ grep -I mój /home/aqsayasin/*.tekst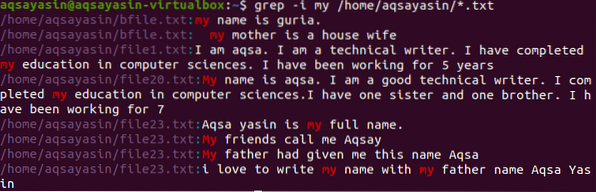
Powyższy obraz pokazuje dane wyjściowe uzyskane z polecenia. „moje” słowo jest podświetlone, czyli w obu przypadkach. Niektóre pliki zawierają go małymi literami, a inne dużymi it. Wyświetlane są również adresy plików i nazwy plików.
Przykład 5
Ten przykład można zastosować do katalogu, w którym znajdują się wszystkie pliki. Ograniczenia zostaną zastosowane, aby wyświetlić konkretny wynik, który pasuje do słowa, które zdefiniowaliśmy w poleceniu. Słowo „jest” służy do wyszukiwania we wszystkich plikach obecnych w systemie.
$ grep -I to /home/aqsayasin/plik*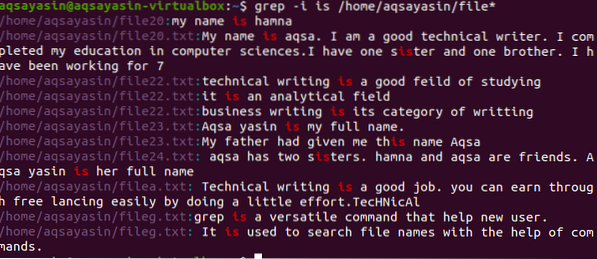
Wynik pokazuje całe łańcuchy zawierające pasujące słowo. Ponieważ „jest” jest pisane osobno lub w połączeniu z innym słowem i.mi. siostra.
Przykład 6
Następne polecenie pokazuje, jak -iw działa razem w poleceniu. Poza tym tutaj wyszukiwanie odbywa się za pomocą dwóch słów w jednym pliku. Odwrotny ukośnik i „|” są używane do opisu dwóch słów w pliku, podczas gdy -w służy do dokładnego dopasowania odpowiedniego słowa w pliku.
$ grep -iw 'hamna\|dom' file21.tekst$ grep 'hamn\|house' file21.tekst

-Zignoruję rozróżnianie wielkości liter. W powyższym przykładzie widzimy, że obecność -w z -I pozwala nie brać pod uwagę domu w pierwszym poleceniu, ponieważ -w pozwala na dokładne dopasowanie. W drugim poleceniu usunęliśmy oba -iw, stąd oba słowa są wyświetlane po dopasowaniu w łańcuchu.
Przykład 7
Więcej niż jedno słowo jest wyszukiwane przy użyciu innej metody. Oba słowa są wyszukiwane z tego samego pliku, te słowa to „praca” i „zarabiaj”. Zarabiaj jest pobierany ze słowa uczenia się i zauważ, że każde słowo jest oddzielone od słowa kluczowego -e.
$ grep -I -e praca -e zarabiaj plika.tekst
Powyższy obrazek pokazuje całe ciągi w akapicie dotyczące słów obecnych w poleceniu. Podobnie jak w powyższych przykładach, - zignorowałem wszystkie przypadki dyskryminacji słów praca i zarabiaj.
Przykład 8
W tym przykładzie wyszukiwanie dwóch słów obecnych we wszystkich plikach .rozszerzenie txt. Te dwa słowa są oddzielone -e, ponieważ -e jest właściwym sposobem rozdzielenia dwóch słów. Uzyskany wynik będzie zawierał oba słowa widoczne we wszystkich plikach z rozszerzeniem tekstowym. Pobierany jest i wyświetlany cały adres pliku. -Zignoruję rozróżnianie wielkości liter i wyświetlę oba słowa obecne we wszystkich plikach.
$ grep -I -e praca -e zarabiaj /home/aqsayasin/*.tekst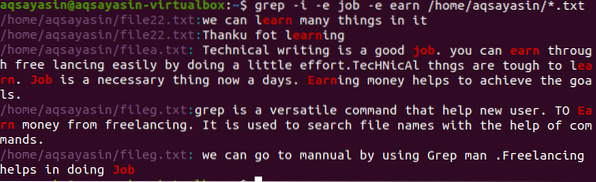
Wniosek
W tym przewodniku użyliśmy najprostszego przykładu, aby rozwinąć koncepcję rozróżniania wielkości liter. Staraliśmy się jak najlepiej przejść przez każdy aspekt, aby poszerzyć wiedzę na temat grep.

