Składnia
Grep [wzór] [nazwa pliku]
Po użyciu grep pojawia się wzór. Wzorzec implikuje sposób, w jaki chcemy go użyć, usuwając dodatkowe miejsce w danych. Zgodnie ze wzorcem opisana jest nazwa pliku, za pomocą którego wykonywany jest wzorzec.
Warunek wstępny
Aby łatwo zrozumieć przydatność grep, musimy mieć zainstalowane Ubuntu w naszym systemie. Podaj dane użytkownika, podając nazwę użytkownika i hasło, aby mieć uprawnienia dostępu do aplikacji systemu Linux. Po zalogowaniu otwórz aplikację i wyszukaj terminal lub użyj klawisza skrótu ctrl+alt+T.
Używając [: blank:] Słowo kluczowe
Załóżmy, że mamy plik o nazwie bfile z rozszerzeniem tekstowym. Możesz utworzyć plik w edytorze tekstu lub za pomocą wiersza poleceń w terminalu. Aby utworzyć plik na terminalu, w tym następujące polecenia:.
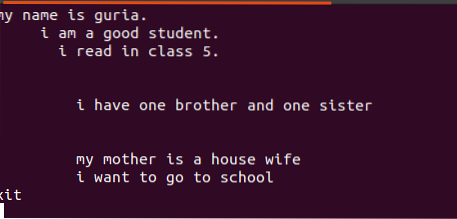
$ Echo “tekst do wprowadzenia do pliku” > nazwa pliku.tekstNie ma potrzeby tworzenia pliku, jeśli jest już obecny. Po prostu wyświetl go za pomocą dołączonego polecenia:
$ nazwa pliku echo.tekstTekst zapisany w tych plikach zawiera spacje między nimi, jak widać na poniższym rysunku.
![]()
Te puste linie można usunąć za pomocą pustego polecenia, aby zignorować puste spacje między słowami lub ciągami.
$ egrep '^[[:puste]]*[^[:puste:]#]' bplik.tekst![]()
Po zastosowaniu zapytania spacje między wierszami zostaną usunięte, a wynik nie będzie już zawierał dodatkowej spacji. Pierwsze słowo jest podświetlane, ponieważ spacje między ostatnim słowem wiersza i między pierwszymi słowami następnego wiersza są usuwane. Możemy również zastosować warunki do tego samego polecenia grep, dodając tę pustą funkcję, aby usunąć niepotrzebne miejsce w danych wyjściowych.
Używając [: spacja:]
Poniżej wyjaśniono inny przykład ignorowania spacji.
Nie wspominając o rozszerzeniu pliku, najpierw wyświetlimy istniejący plik za pomocą polecenia.
$ cat file20![]()
Przyjrzyjmy się, jak usuwana jest dodatkowa spacja za pomocą polecenia grep oprócz słowa kluczowego [: space:]. Opcja -v Grepa pomoże wypisać wiersze bez pustych wierszy i z dodatkowymi odstępami, które są również uwzględnione w formie akapitu.
$ grep -v '^[[;spacja:]]*$' plik20Zobaczysz, że dodatkowe wiersze są usuwane, a dane wyjściowe są uporządkowane w kolejności wierszowej. W ten sposób metodologia grep -v jest tak pomocna w osiągnięciu wymaganego celu.
![]()
Wzmianki o rozszerzeniach plików ograniczają funkcjonalność grep do działania tylko na określonych rozszerzeniach plików, i.mi., .tekst lub .mp3. Gdy wykonamy wyrównanie na pliku tekstowym, weźmiemy fileg.txt jako przykładowy plik. Najpierw wyświetlimy obecny w nim tekst za pomocą funkcji $cat. Dane wyjściowe są następujące:
![]()
Po zastosowaniu polecenia uzyskaliśmy nasz plik wyjściowy. Tutaj możemy zobaczyć dane bez odstępów między wierszami, które są kolejno zapisywane.
$ grep -v '^[[:spacja:]]*$' plikg.tekst![]()
Oprócz długich poleceń możemy również użyć krótkich poleceń pisanych w Linuksie i Unixie, aby zaimplementować w nim grep obsługujące skrócone znaki.
$ grep '\s' nazwa pliku.tekstWidzieliśmy, jak dane wyjściowe są uzyskiwane przez zastosowanie poleceń z danych wejściowych. Tutaj dowiemy się, w jaki sposób dane wejściowe są utrzymywane z powrotem z danych wyjściowych.
$ grep '\S' nazwa pliku.txt > tmp.txt && mv tmp.nazwa pliku txt.tekstTutaj użyjemy tymczasowego pliku tekstowego z rozszerzeniem o nazwie tmp.
Używając ^#
Podobnie jak w innych opisanych przykładach, zastosujemy polecenie do pliku tekstowego za pomocą polecenia cat. Możemy również wyświetlić tekst za pomocą polecenia echo.
$ nazwa pliku echo.tekstPlik tekstowy zawiera 4 wiersze z odstępem między nimi. Te linie odstępu można łatwo usunąć za pomocą określonego polecenia.
![]()
Regularne operacje rozszerzone są włączane przez -E, co pozwala na wszystkie wyrażenia regularne, zwłaszcza potok. Rurka jest używana jako opcjonalny warunek „lub” w dowolnym wzorze.”^#”. Pokazuje dopasowanie wierszy tekstu w pliku zaczynających się od znaku #. „^$” dopasuje się do wszystkich wolnych miejsc w tekście lub pustych wierszach.
![]()
Dane wyjściowe pokazują całkowite usunięcie dodatkowej przestrzeni między wierszami obecnymi w pliku danych. W tym przykładzie widzieliśmy, że w poleceniu „^#” jest pierwsze, co oznacza, że tekst jest dopasowywany jako pierwszy. „^$” pojawia się po | operatora, więc wolne miejsce jest później dopasowywane.
Używając ^$
Podobnie jak w powyższym przykładzie, otrzymamy te same wyniki, ponieważ polecenie jest prawie takie samo. Jednak wzór jest napisany odwrotnie. Plik22.txt to plik, którego użyjemy do usuwania spacji.
![]()
Stosowana jest ta sama metodologia z wyjątkiem pracy z priorytetem. Zgodnie z tym poleceniem najpierw dopasowywane są wolne spacje, a następnie dopasowywane są pliki tekstowe. Dane wyjściowe zapewnią sekwencję linii, usuwając w nich dodatkowe luki.
![]()
Inne proste polecenia
- Grep '^…' nazwa pliku.
- Grep '.' Nazwa pliku
Oba są tak proste i pomagają w usuwaniu luk w wierszach tekstu.
Wniosek
Usuwanie zbędnych luk w plikach za pomocą wyrażeń regularnych to dość łatwe podejście do uzyskania płynnej sekwencji danych i zachowania spójności. Przykłady są szczegółowo wyjaśnione, aby wzbogacić informacje dotyczące tematu your.


