Zadania zastępcze można wykonywać w Linuksie na różne sposoby. Polecenie „sed” jest jednym ze sposobów wykonania zadania zastępczego. To polecenie może być użyte do zastąpienia tekstu w ciągu znaków lub pliku przy użyciu innego wzorca. Jak możesz zastąpić wszystko po dopasowaniu wzorca za pomocą polecenia 'sed' jest pokazane w tym samouczku.
Zamień wszystko po dopasowaniu w ciągu:
Jak można zastąpić część ciągu na podstawie pasującego wzorca i kolumny $PARTITION_COLUMN pokazano w tej sekcji tego samouczka. Ale ta zmienna działa, jeśli wzorzec pasuje do dowolnego słowa na początku lub w środku ciągu. Nie zastąpi tekstu, jeśli wzorzec pasuje do ostatniego słowa ciągu.
Przykład-1: Zamień wszystko po dopasowaniu za pomocą $PARTITION_COLUMN
Poniższe polecenie przeszuka znak 'a', a pozostała część po 'a' zostanie zastąpiona tekstem „popularna witryna blogowa”. $PARTITION_COLUMN.* służy do określenia pozostałej części po znaku „a”.
$ echo "LinuxHint to strona internetowa" | sed "s/a $PARTITION_COLUMN.*/popularny blog/"Następujące dane wyjściowe pojawią się po uruchomieniu polecenia. Tutaj „witryna” została zastąpiona przez „popularną witrynę bloga”.

Poniższy wzorzec spowoduje wyszukanie słowa „sieć„ w ciągu i zastąp pozostałą część znakiem ”sieć„przez tekst”popularna witryna blogowa' jeśli dopasowanie istnieje i 'sieć„ nie jest częścią ostatniego słowa ciągu”.
Następujące dane wyjściowe pojawią się po uruchomieniu polecenia. Tutaj „witryna” jest ostatnim słowem ciągu i z tego powodu nie dokonano żadnej zamiany.

Przykład-2: Zamień wszystko po dopasowaniu za pomocą wzorca
Następujące polecenie wyszuka słowo „grzmotnąć' globalnie w ciągu i zastąp wszystko słowem, jeśli słowo istnieje w ciągu. 'sol' jest tutaj używane do wyszukiwania globalnego.
$ echo "Lubię programowanie w bashu" | sed "s/bash.*/skrypt Pythona/g"Następujące dane wyjściowe pojawią się po uruchomieniu polecenia. Tutaj 'bash' istnieje w środku ciągu, a zamiana została wykonana.

Zastąp wszystko po dopasowaniu w pliku:
Cała zawartość określonego wiersza lub wiele wierszy lub pozostałe wiersze pliku po dopasowaniu można zastąpić za pomocą 'sed' Komenda. Utwórz plik tekstowy o nazwie frekwencja.tekst z następującą treścią, aby przetestować przykłady pokazane w tej sekcji.
frekwencja.tekst
1108885 jest obecny1999979 jest obecny
1769994 jest nieobecny
1105656 jest nieobecny
1455999 jest nieobecny
Przykład -3: Zamień całą zawartość z wiersza pliku po dopasowaniu
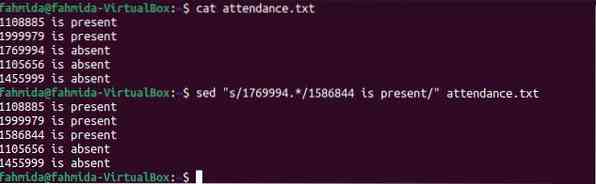
Następujące polecenie „sed” wyszuka numer 1769994 w pliku, a wszystko z numerem zostanie zastąpione tekstem „1586844 jest obecny”, jeśli numer istnieje w dowolnym wierszu pliku.
$ przynależność kota.tekst$ sed "s/1769994.*/1586844 jest obecny/" frekwencja.tekst
Następujące dane wyjściowe pojawią się podczas uruchamiania poleceń. Tutaj numer wyszukiwania znajduje się w trzecim wierszu pliku, a podmiana została wykonana.
Przykład -4: Zamień całą zawartość z wielu wierszy pliku po dopasowaniu
Następujące polecenie sed pokazuje użycie zmiennej $PARTITION_COLUMN do zastąpienia wielu wierszy z pliku. Polecenie przeszuka „110” na początku każdego wiersza pliku i zamieni wszystko na „110” tekstem „Nieprawidłowy wpis”, w którym zostanie znaleziony pasujący tekst.
$ frekwencja kota.tekst$ sed "s/^110.* $PARTITION_COLUMN.*/Nieprawidłowy wpis/" frekwencja.tekst
Następujące dane wyjściowe pojawią się po uruchomieniu poleceń. „110” istnieje w dwóch wierszach pliku, które zostały zastąpione tekstem zastępującym.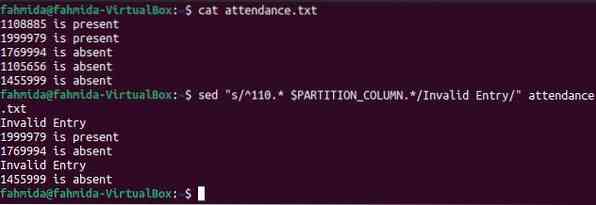
Przykład-5: Zastąp całą zawartość wiersza pliku za pomocą „c” po dopasowaniu
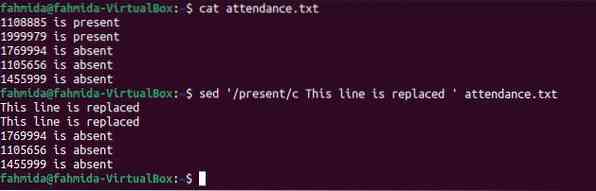
Następujące 'sedPolecenie ' pokazuje użycie 'do'zamienić wszystko po meczu. Tutaj 'do' oznacza zmianę. Polecenie wyszuka słowo ”teraźniejszość' w pliku i zastąp całą linię tekstem, 'Ta linia jest zastąpiona' jeśli słowo istnieje w dowolnym wierszu pliku.
$ frekwencja kota.tekst$ sed '/obecny/c Ta linia jest zastąpiona ' frekwencja.tekst
Następujące dane wyjściowe pojawią się po uruchomieniu poleceń. Słowo „obecny” znajduje się w pierwszych dwóch wierszach pliku, a te dwa wiersze zostały zastąpione tekstem zastępującym.
Przykład-6: Zamień całą zawartość z wiersza pliku na podstawie wzorca początkowego i końcowego
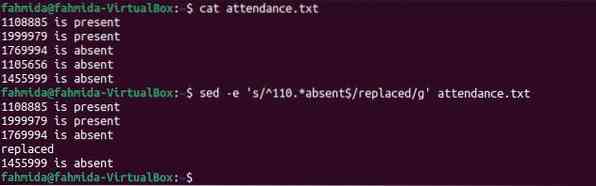
Czasami konieczne jest zastąpienie tekstu na podstawie wzorca początkowego i końcowego. Poniższe polecenie 'sed' pokazuje sposób definiowania wzorców początkowych i końcowych w celu zastąpienia wierszy z pliku. Polecenie przeszuka te wiersze w pliku, które zaczynają się od numeru 110 i kończą słowem „nieobecny” i zastąpi wszystko słowem „zastąpiono” w miejscach, w których wzorce pasują.
$ frekwencja kota.tekst$ sed -e 's/^110.*brak $/zastąpiony/g' frekwencja.tekst
Następujące dane wyjściowe pojawią się po uruchomieniu poleceń. Tutaj pierwszy i czwarty wiersz zaczynają się od liczby 110, ale słowo „nieobecny” występuje tylko w czwartym wierszu. Tak więc czwarty wiersz pliku został zastąpiony tekstem zastępującym replacing.
Wniosek:
Polecenie „sed” to bardzo potężne narzędzie systemu Linux do wykonywania różnych typów zadań związanych z przetwarzaniem tekstu. Zadanie zastępowania oparte na dopasowanym wzorcu jest omówione w tym samouczku przy użyciu różnych typów wzorców w poleceniu 'sed'. $PARTITION_COLUMN, 'c' i '.*' jest używany w tym samouczku, aby zastąpić całą linię pliku, w której istnieje pasujący wzorzec. Pokazano tu zastosowania niektórych znaków definiujących wzorce, takich jak „^” i „$”. Istnieje wiele innych znaków definiujących wzorzec w wyrażeniu regularnym do celów wyszukiwania. Mam nadzieję, że ten samouczek pomoże czytelnikowi poznać podstawy zastępowania wszystkiego z pliku po meczu.


