Format pliku CSV jest najczęściej używany do obsługi baz danych i arkuszy kalkulacyjnych. Pierwszy wiersz w pliku CSV jest najczęściej używany do definiowania pól kolumn, podczas gdy pozostałe wiersze są uważane za wiersze. Ta struktura pozwala użytkownikom prezentować dane tabelaryczne za pomocą plików CSV. Pliki CSV można edytować w dowolnym edytorze tekstu. Jednak aplikacje takie jak LibreOffice Calc zapewniają zaawansowane narzędzia do edycji, sortowania i filtrowania.
Odczytywanie danych z plików CSV za pomocą Pythona
Moduł CSV w Pythonie pozwala czytać, pisać i manipulować dowolnymi danymi przechowywanymi w plikach CSV. Aby odczytać plik CSV, będziesz musiał użyć metody „reader” z modułu „csv” Pythona, który jest zawarty w standardowej bibliotece Pythona.
Weź pod uwagę, że masz plik CSV zawierający następujące dane:
Mango, Banan, Jabłko, Pomarańcza50,70,30,90
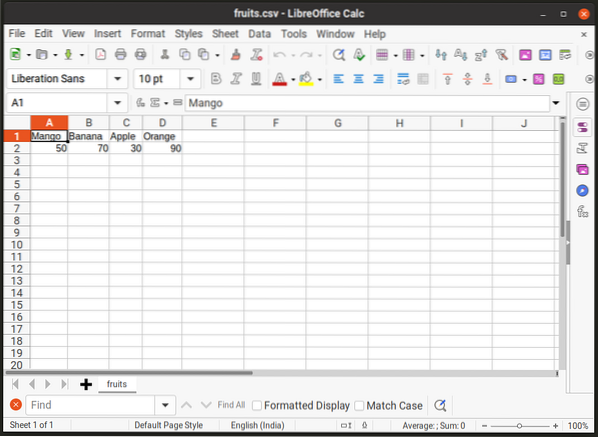
Pierwszy wiersz pliku definiuje każdą kategorię kolumny, w tym przypadku nazwę owoców. Druga linia przechowuje wartości pod każdą kolumną (zapasy). Wszystkie te wartości są oddzielone przecinkiem. Jeśli miałbyś otworzyć ten plik w aplikacji do obsługi arkuszy kalkulacyjnych, takiej jak LibreOffice Calc, wyglądałoby to tak:
Teraz przeczytaj wartości z „owoców”.csv” używając modułu „csv” Pythona, będziesz musiał użyć metody „reader” w następującym formacie:
importuj csvz open("owoce.csv") jako plik:
czytnik_danych = csv.czytnik(plik)
dla linii w data_reader:
druk (linia)
Pierwsza linia w powyższym przykładzie importuje moduł „csv”. Następnie polecenie „z otwartymi” służy do bezpiecznego otwarcia pliku zapisanego na dysku twardym („owoce.csv” w tym przypadku). Nowy obiekt „data_reader” jest tworzony przez wywołanie metody „reader” z modułu „csv”. Ta metoda „czytnika” przyjmuje nazwę pliku jako obowiązkowy argument, więc odwołanie do „owoców.csv” jest do niego przekazywany. Następnie uruchamiana jest instrukcja pętli „for”, która wyświetla każdy wiersz z „owoców.plik csv. Po uruchomieniu przykładowego kodu wspomnianego powyżej, powinieneś otrzymać następujące dane wyjściowe:
['50', '70', '30', '90']Jeśli chcesz przypisać numery linii do wyjścia, możesz użyć funkcji „enumerate”, która przypisuje numer do każdego elementu w iteracji (zaczynając od 0, chyba że zostanie zmieniony).
importuj csvz open("owoce.csv") jako plik:
czytnik_danych = csv.czytnik(plik)
dla indeksu wiersz w enumerate(data_reader):
druk (indeks, linia)
Zmienna „indeks” utrzymuje licznik dla każdego elementu. Po uruchomieniu przykładowego kodu wspomnianego powyżej, powinieneś otrzymać następujące dane wyjściowe:
0 ['Mango', 'Banan', 'Jabłko', 'Pomarańcza']1 ['50', '70', '30', '90']
Ponieważ pierwszy wiersz w pliku „csv” zazwyczaj zawiera nagłówki kolumn, możesz użyć funkcji „enumerate”, aby wyodrębnić te nagłówki:
importuj csvz open("owoce.csv") jako plik:
czytnik_danych = csv.czytnik(plik)
dla indeksu, wiersz w enumerate(data_reader):
jeśli indeks == 0:
nagłówki = linia
druk (nagłówki)
Blok „if” w powyższym oświadczeniu sprawdza, czy indeks jest równy zero (pierwsza linia w „fruits.csv”). Jeśli tak, to wartość zmiennej „line” jest przypisywana do nowej zmiennej „headings”. Po uruchomieniu powyższego przykładu kodu powinieneś otrzymać następujące dane wyjściowe:
['Mango', 'Banan', 'Jabłko', 'Pomarańcza']Pamiętaj, że możesz użyć własnego ogranicznika podczas wywoływania „csv.czytnik” przy użyciu opcjonalnego argumentu „delimiter” w następującym formacie:
importuj csvz open("owoce.csv") jako plik:
czytnik_danych = csv.czytnik(plik, ogranicznik = ";")
dla linii w data_reader:
druk (linia)
Ponieważ w pliku csv każda kolumna jest powiązana z wartościami w wierszu, możesz chcieć utworzyć obiekt „słownik” Pythona podczas odczytywania danych z pliku „csv”. Aby to zrobić, musisz użyć metody „DictReader”, jak pokazano w poniższym kodzie:
importuj csvz open("owoce.csv") jako plik:
czytnik_danych = csv.DictReader(plik)
dla linii w data_reader:
druk (linia)
Po uruchomieniu przykładowego kodu wspomnianego powyżej, powinieneś otrzymać następujące dane wyjściowe:
'Mango': '50', 'Banan': '70', 'Jabłko': '30', 'Pomarańczowy': '90'Masz teraz obiekt słownika, który kojarzy poszczególne kolumny z odpowiadającymi im wartościami w wierszach. Działa to dobrze, jeśli masz tylko jeden wiersz. Załóżmy, że „owoce”.plik csv” zawiera teraz dodatkowy wiersz określający, ile dni zajmie wyczerpanie zapasu owoców.
Mango, banan, jabłko, pomarańcza50,70,30,90
3,1,6,4
Jeśli masz wiele wierszy, uruchomienie tego samego przykładowego kodu powyżej spowoduje uzyskanie różnych danych wyjściowych.
'Mango': '50', 'Banan': '70', 'Jabłko': '30', 'Pomarańczowy': '90''Mango': '3', 'Banan': '1', 'Jabłko': '6', 'Pomarańczowy': '4'
Może to nie być idealne ponieważ możesz chcieć odwzorować wszystkie wartości dotyczące jednej kolumny na jedną parę klucz-wartość w słowniku Pythona. Zamiast tego wypróbuj ten przykładowy kod:
importuj csvz open("owoce.csv") jako plik:
czytnik_danych = csv.DictReader(plik)
data_dict =
dla linii w data_reader:
dla klucza wartość w wierszu.przedmiotów():
data_dict.setdefault(klawisz, [])
data_dict[klucz].dołącz(wartość)
drukuj (data_dict)
Po uruchomieniu przykładowego kodu wspomnianego powyżej, powinieneś otrzymać następujące dane wyjściowe:
'Mango': ['50', '3'], 'Banan': ['70', '1'], 'Jabłko': ['30', '6'], 'Pomarańczowy': ['90 ', '4']Pętla „for” jest używana na każdym elemencie obiektu „DictReader”, aby zapętlić pary klucz-wartość. Nowa zmienna słownikowa Pythona „data_dict” została wcześniej zdefiniowana. Będzie przechowywać ostateczne mapowania danych. Pod drugim blokiem pętli „for” użyto metody „setdefault” słownika Pythona. Ta metoda przypisuje wartość do klucza słownika. Jeśli para klucz-wartość nie istnieje, tworzona jest nowa z podanych argumentów. Więc w tym przypadku nowa pusta lista zostanie przypisana do klucza, jeśli jeszcze nie istnieje. Na koniec „wartość” jest dodawana do odpowiedniego klucza w końcowym obiekcie „data_dict”.
Zapisywanie danych do pliku CSV
Aby zapisać dane do pliku „csv” należy użyć metody „writer” z modułu „csv”. Poniższy przykład doda nowy wiersz do istniejących „owoców.plik csv.
importuj csvz open("owoce.csv", "a") jako plik:
data_writer = csv.pisarz(plik)
data_writer.wpisuj([3,1,6,4])
Pierwsza instrukcja otwiera plik w trybie „dołącz”, oznaczonym argumentem „a”. Następnie wywoływana jest metoda „writer” i odwołanie do „owoców.plik csv” jest do niego przekazywany jako argument. Metoda „writerow” zapisuje lub dodaje nowy wiersz do pliku.
Jeśli chcesz przekonwertować słownik Pythona na strukturę plików „csv” i zapisać wynik w pliku „csv”, wypróbuj ten kod:
importuj csvz open("owoce.csv", "w") jako plik:
nagłówki = ["Mango", "Banan", "Jabłko", "Pomarańczowy"]
data_writer = csv.DictWriter(plik, nazwy pól=nagłówki)
data_writer.nagłówek zapisu()
data_writer.writerow("Mango": 50, "Banan": 70, "Jabłko": 30, "Pomarańczowy": 90)
data_writer.writerow("Mango": 3, "Banan": 1, "Jabłko": 6, "Pomarańczowy": 4)
Po otwarciu pustych „owoców”.csv” za pomocą instrukcji „z otwartymi” definiowana jest nowa zmienna „headings” zawierająca nagłówki kolumn. Nowy obiekt „data_writer” jest tworzony przez wywołanie metody „DictWriter” i przekazanie jej referencji do „owoców.csv” i argument „fieldnames”. W następnym wierszu nagłówki kolumn są zapisywane do pliku przy użyciu metody „writeheader”. Ostatnie dwie instrukcje dodają nowe wiersze do odpowiadających im nagłówków utworzonych w poprzednim kroku.
Wniosek
Pliki CSV zapewniają zgrabny sposób zapisywania danych w formacie tabelarycznym. Wbudowany moduł „csv” Pythona ułatwia obsługę danych dostępnych w plikach „csv” i implementację na nich dalszej logiki.


